


 软件简介
软件简介
Stata是一种统计分析和数据管理软件,它提供了所有数据科学所需的数据操作、可视化、统计和可重复报告功能。广泛用于学术研究、市场调研、医学研究等领域。它具有强大的数据分析能力,可以进行各种统计分析、回归分析、时间序列分析、生存分析等。此外,Stata还提供了数据管理功能,包括数据清洗、变量管理、数据合并等。
最新更新
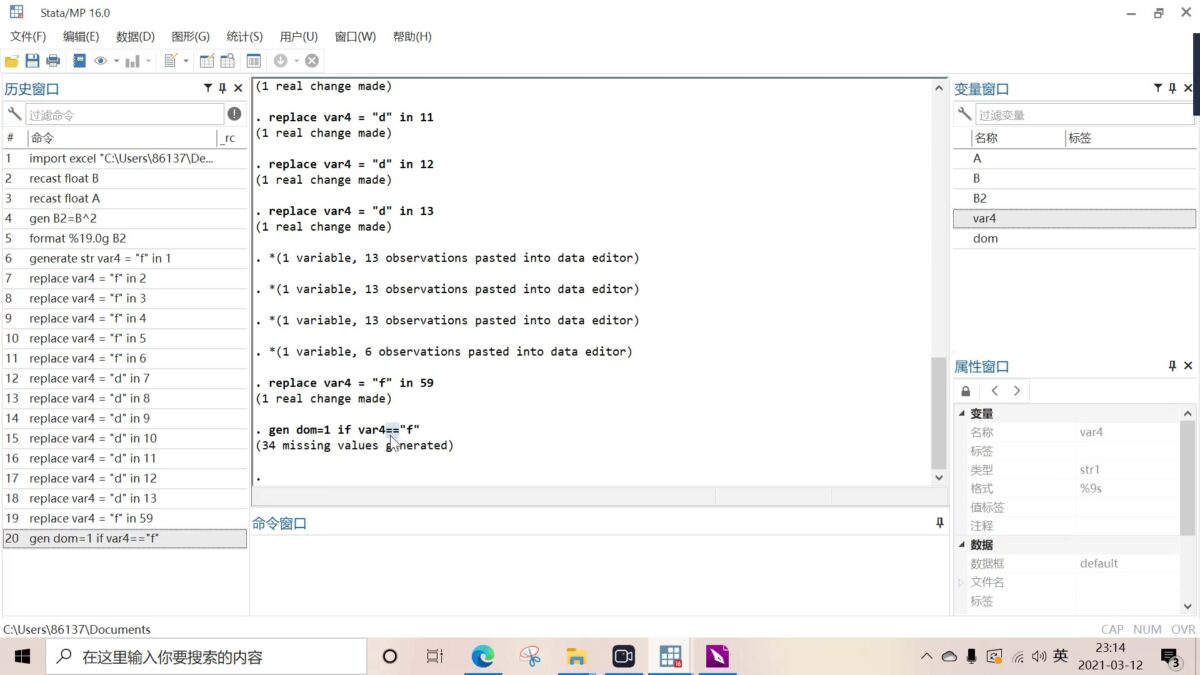
 一般来说,你会选择一个模型并基于这个模型进行分析。这些结果是以所选模型为条件的。在存在多个合理的模型时,这种方法可能不可靠。模型平均法允许你在多个模型的基础上进行分析,从而在结果中考虑到模型的不确定性。BMA根据贝叶斯原则对模型的不确定性进行核算,可以普遍应用于任何数据分析。在回归设定中,模型的不确定性描述了哪些预测因子应该包括在回归模型中的不确定性。新的命令 bmaregress 可以执行线性回归的 BMA,并可用于推理、 预测,如果需要的话,甚至可以用于模型选择。比如说,. bmaregress y x1 x2考虑包括或不包括预测因子x1和x2的结果y的所有四种可能的模型,并根据每个模型在观察数据基础上的可能性结合这些模型。你可以从各种先验分布中选择,以探索关于模型和预测者的重要性的假设对结果的影响。Postestimation 命令允许你估计一个模型的概率,识别重要的预测因子,探索模型的复杂性,获得预测手段,评估预测性能,并对回归系数进行推断。使用线性回归,bmaregress 对线性回归模型进行 BMA,使研究人员能够考虑到应该使用哪些预测因子的不确定性。
一般来说,你会选择一个模型并基于这个模型进行分析。这些结果是以所选模型为条件的。在存在多个合理的模型时,这种方法可能不可靠。模型平均法允许你在多个模型的基础上进行分析,从而在结果中考虑到模型的不确定性。BMA根据贝叶斯原则对模型的不确定性进行核算,可以普遍应用于任何数据分析。在回归设定中,模型的不确定性描述了哪些预测因子应该包括在回归模型中的不确定性。新的命令 bmaregress 可以执行线性回归的 BMA,并可用于推理、 预测,如果需要的话,甚至可以用于模型选择。比如说,. bmaregress y x1 x2考虑包括或不包括预测因子x1和x2的结果y的所有四种可能的模型,并根据每个模型在观察数据基础上的可能性结合这些模型。你可以从各种先验分布中选择,以探索关于模型和预测者的重要性的假设对结果的影响。Postestimation 命令允许你估计一个模型的概率,识别重要的预测因子,探索模型的复杂性,获得预测手段,评估预测性能,并对回归系数进行推断。使用线性回归,bmaregress 对线性回归模型进行 BMA,使研究人员能够考虑到应该使用哪些预测因子的不确定性。
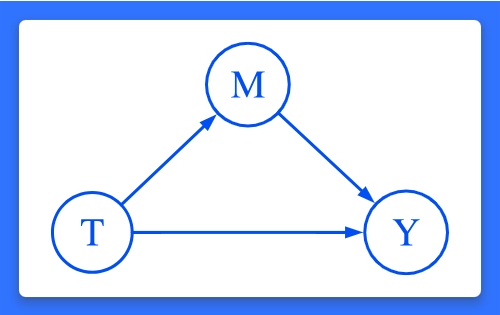 因果推理的目的是识别和量化治疗对结果的因果效应。在因果关系分析中,我们旨在进一步探索这种效应是如何产生的。也许运动可以提高一种激素的水平,而这种激素反过来又可以提高幸福感。也许进口配额增加了当地公司的市场力量,反过来又增加了商品的价格。 我们经常用因果图来显示这样的关系,比如说
因果推理的目的是识别和量化治疗对结果的因果效应。在因果关系分析中,我们旨在进一步探索这种效应是如何产生的。也许运动可以提高一种激素的水平,而这种激素反过来又可以提高幸福感。也许进口配额增加了当地公司的市场力量,反过来又增加了商品的价格。 我们经常用因果图来显示这样的关系,比如说
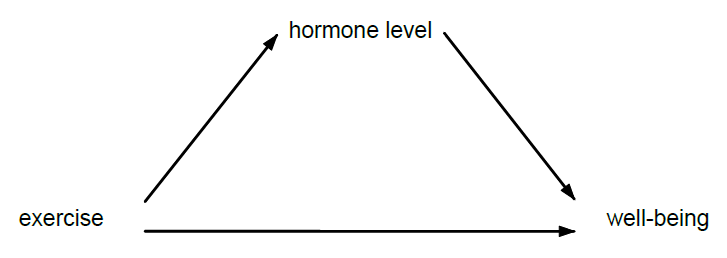
利用新的 mediate 命令,我们可以估计治疗对结果的总效应,并将其分解为直接效应和间接效应(通过中介如荷尔蒙水平)。事实上,可以计算多种类型的分解,这取决于感兴趣的假设。此外,estat proportion 报告了通过中介物发生的总效应的比例。 mediate 是非常灵活的--结果可以是连续的、二进制的或计数的;mediator 可以是连续的、二进制的或计数的;而治疗结果可以是二进制的、多值的或连续的。 mediate 是命令非常灵活的,它支持结果和调解人的24种模型组合,所以它可以应用于实际研究中出现的许多情况。
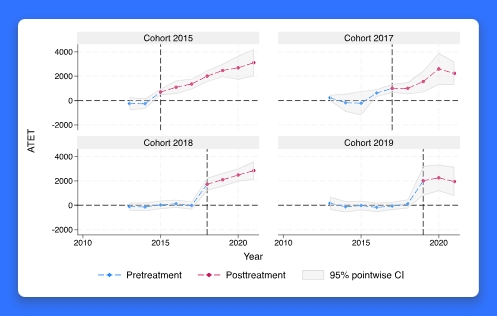 DID 模型是用来估计重复测量数据对被治疗者的平均治疗效果(ATET)的。治疗效果可以是药物治疗对血压的影响或培训计划对就业的影响。与现有的teffects命令提供的标准横断面分析不同,DID 分析在估计 ATET 时控制了组和时间效应,其中组是重复测量的。异质性 DID 模型还考虑了因群体在不同时间点接受治疗而产生的治疗效果的变化,以及群体内效果随时间变化的情况。假设几个学校引进了一项运动和营养计划,以改善学生的健康状况。该计划对学生健康结果的影响不随时间变化,而且无论何时采用该计划都是一样的,这是否合理?也许不是。我们可以使用异质性 DID 模型来解释潜在的效果差异。新的命令 hdidregress 和 xthdidregress 适用于异质 DID 模型。hdidregress 适用于重复截面数据,xthdidregress 适用于纵向/面板数据。异质性 DID 是最近世界各地许多 Stata 会议上的一个热门话题。现有的用户可能会对这个新增功能感到非常兴奋。
DID 模型是用来估计重复测量数据对被治疗者的平均治疗效果(ATET)的。治疗效果可以是药物治疗对血压的影响或培训计划对就业的影响。与现有的teffects命令提供的标准横断面分析不同,DID 分析在估计 ATET 时控制了组和时间效应,其中组是重复测量的。异质性 DID 模型还考虑了因群体在不同时间点接受治疗而产生的治疗效果的变化,以及群体内效果随时间变化的情况。假设几个学校引进了一项运动和营养计划,以改善学生的健康状况。该计划对学生健康结果的影响不随时间变化,而且无论何时采用该计划都是一样的,这是否合理?也许不是。我们可以使用异质性 DID 模型来解释潜在的效果差异。新的命令 hdidregress 和 xthdidregress 适用于异质 DID 模型。hdidregress 适用于重复截面数据,xthdidregress 适用于纵向/面板数据。异质性 DID 是最近世界各地许多 Stata 会议上的一个热门话题。现有的用户可能会对这个新增功能感到非常兴奋。
 Stata 18 中的 graph 有了新的外观!
Stata 18 中的 graph 有了新的外观!
新的默认图形方案(或 Stata 图形的新外观)包括以下备受期待的功能:
1.白色背景
2.更新的调色板,色彩明亮
3.水平 y 轴标签
4.宽高比
5.某些图形的动态图例放置
6.还有更多
作为一个例子,新方案中的条形图现在就像下面一样:
从而代替了以下旧条形图:
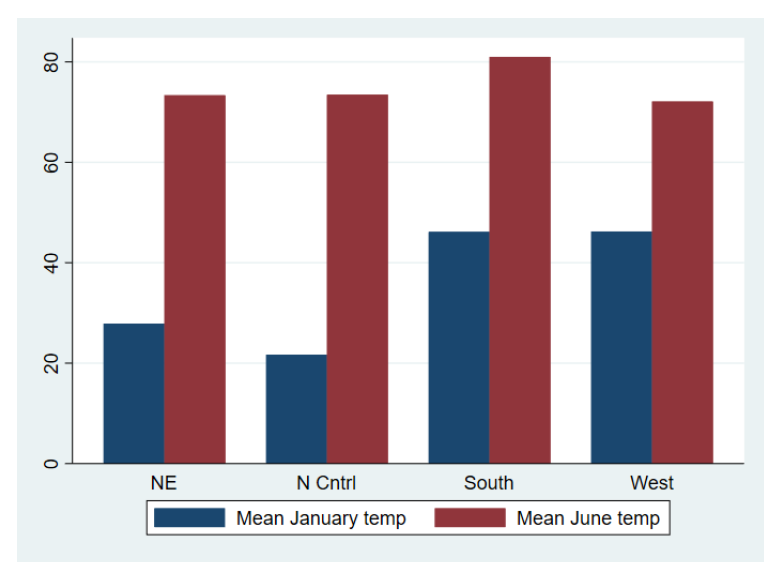
事实上,我们引入了四种新的图方案:stcolor、stcolor_alt、stgcolor和stgcolor_alt。新的默认为 stcolor,其他方案是 stcolor 的变体,提供不同的宽度和图例位置。
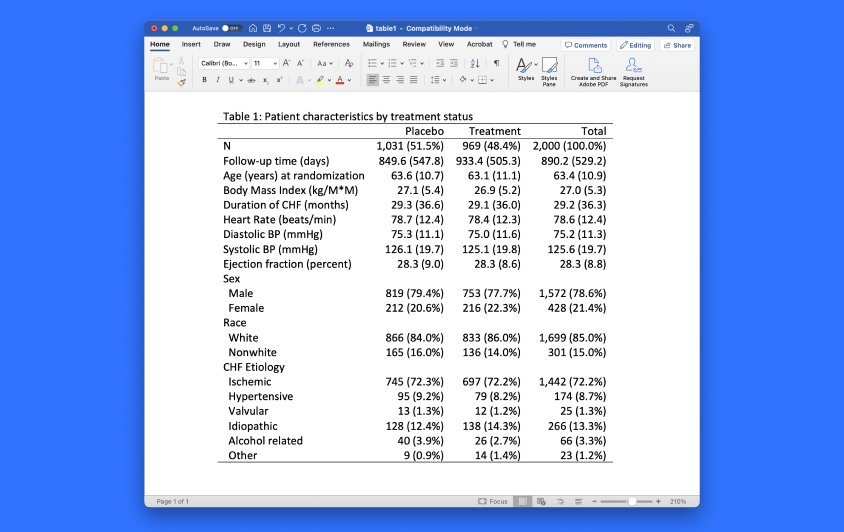 新的 dtable 命令创建一个描述性统计表。dtable 报告连续和分类因素变量的汇总统计。你可以选择你想为每个变量报告的统计数字;从平均数、标准差、中位数、四分位数范围、百分比、比例和许多其他数据中选择。你还可以轻松地比较另一个变量的不同类别的统计数据。由 dtable 创建的表格可以在许多方面进行定制--要报告的统计数据、数字和字符串格式、注释、标题、标签等等。表格可以直接导出到 Microsoft Word 、MicrosoftExcel。HTML。Markdown,PDF。LaTex SMCL. 或纯文本。dtable 命令使创建那些通常被称为 "表1 "的表格变得很容易-几乎每篇研究论文中都有第一个表格。
新的 dtable 命令创建一个描述性统计表。dtable 报告连续和分类因素变量的汇总统计。你可以选择你想为每个变量报告的统计数字;从平均数、标准差、中位数、四分位数范围、百分比、比例和许多其他数据中选择。你还可以轻松地比较另一个变量的不同类别的统计数据。由 dtable 创建的表格可以在许多方面进行定制--要报告的统计数据、数字和字符串格式、注释、标题、标签等等。表格可以直接导出到 Microsoft Word 、MicrosoftExcel。HTML。Markdown,PDF。LaTex SMCL. 或纯文本。dtable 命令使创建那些通常被称为 "表1 "的表格变得很容易-几乎每篇研究论文中都有第一个表格。
 从 Stata 16 开始,Stata 就支持内存中的多个数据集。每个数据集都驻留在一个 frame 中。当数据集是相关的,你可以通过使用 frlink 命令来链接它们的 frame,并确定当 frame 中的观测值与相关 frame 中的观测值相匹配的变量。
从 Stata 16 开始,Stata 就支持内存中的多个数据集。每个数据集都驻留在一个 frame 中。当数据集是相关的,你可以通过使用 frlink 命令来链接它们的 frame,并确定当 frame 中的观测值与相关 frame 中的观测值相匹配的变量。
在 Stata 18 中,你可以使用新的 fralias add 命令来创建跨链接 frame 的别名变量,并轻松地使用存储在不同 frame 中的变量进行分析。别名变量的行为就像你把它们从一个 frame 中复制到另一个 frame 中一样,但是由于它们被存储在原始 frame 中,所以它们占用的内存非常小。要查看别名变量的使用很容易,请假设 y 是当前 frame 中的一个变量,并且 x 可以从名为 frame2 的链接中获得。要在当前 frame 中创建x的别名,请输入:. fralias add x, from(frame2)然后,您可以通过输入:. regress y x就像 x 被存储在当前 frame 中一样。
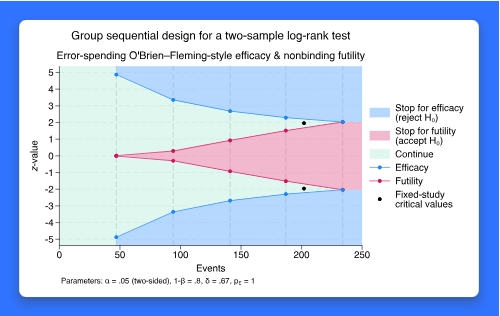 GSDs 是一种适应性设计,允许研究人员在发现某种治疗方法有效或无效的有力证据时提前停止试验。假设我们想设计一项研究来检验某种类型的化疗对治疗肿瘤是否有效,并且我们希望在几个月的时间里收集数据。GSDs 允许我们在收集数据时进行中期分析,而不是在收集完所有数据后进行一次分析。每个中期分析都提供了停止试验或继续收集数据的机会。如果有强有力的证据证明疗效,试验可以提前停止。如果有强有力的证据表明试验是无效的,试验也可以提前停止;这样可以避免让更多的参与者接受不适当的治疗。Stata 18 为 GSDs 提供了一套命令。新的 gsbounds 命令可以根据分析的数量(也叫looks)、期望的总体 Type I 误差和期望的功率来计算疗效和效用界限。新的 Gsdesign 命令可以计算疗效和无效边界,并提供中期和最终分析的样本量,以测试平均值、比例和生存函数。 Graphs 使所有中期和最终分析的界限更容易直观化。这个工具对用户非常友好。syntax 命令遵循我们对 power 命令的直接 syntax。通过点选界面可以很容易地获得结果。样本大小的计算可以扩展到均值、比例和生存函数的测试之外,因为用户可以指定一个用户定义的方法,这些通过 gsdesign 随时可用。任何设计临床试验的人都会对此功能感兴趣,这可以扩展到临床心理学家和其他医学研究人员。
GSDs 是一种适应性设计,允许研究人员在发现某种治疗方法有效或无效的有力证据时提前停止试验。假设我们想设计一项研究来检验某种类型的化疗对治疗肿瘤是否有效,并且我们希望在几个月的时间里收集数据。GSDs 允许我们在收集数据时进行中期分析,而不是在收集完所有数据后进行一次分析。每个中期分析都提供了停止试验或继续收集数据的机会。如果有强有力的证据证明疗效,试验可以提前停止。如果有强有力的证据表明试验是无效的,试验也可以提前停止;这样可以避免让更多的参与者接受不适当的治疗。Stata 18 为 GSDs 提供了一套命令。新的 gsbounds 命令可以根据分析的数量(也叫looks)、期望的总体 Type I 误差和期望的功率来计算疗效和效用界限。新的 Gsdesign 命令可以计算疗效和无效边界,并提供中期和最终分析的样本量,以测试平均值、比例和生存函数。 Graphs 使所有中期和最终分析的界限更容易直观化。这个工具对用户非常友好。syntax 命令遵循我们对 power 命令的直接 syntax。通过点选界面可以很容易地获得结果。样本大小的计算可以扩展到均值、比例和生存函数的测试之外,因为用户可以指定一个用户定义的方法,这些通过 gsdesign 随时可用。任何设计临床试验的人都会对此功能感兴趣,这可以扩展到临床心理学家和其他医学研究人员。
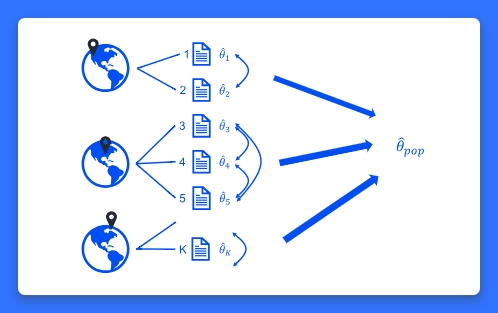 当研究人员想要分析来自多个研究的结果时,他们会使用元分析来合并结果并估计总体效应大小。现有的 meta 套件被用来进行标准和多变量的元分析。有时报告的效应大小被嵌套在更高层次的分组中,如地理位置(州或国家)或行政单位(学区)。同一组内(例如,区)的效应大小很可能是相似的,因此具有依赖性。在这种情况下,你可以使用多层元分析。多层元分析的目标是不仅要综合总体效应大小,而且要考虑到这种依赖性,并评估不同层次的效应大小之间的变化。新的估计命令 meta meregress 和 meta multilevel 是用来进行多层元分析的。假设我们有研究报告了两种教学方法对数学考试成绩y和y的抽样标准误差的影响(平均差异)。影响大小嵌套在学校内,学校嵌套在地区内。我们可以用. meta meregress y || district: || school:, essevariable(se)或. meta multilevel y, relevels(district school) essevariable(se)如果我们有协变量并想要包括随机斜率,我们可以使用meta meregress:. meta meregress y x1 x2 || district: x1 x2 || school:, essevariable(se)拟合模型后,后估计命令可用于计算多层次异质性统计,显示估计的随机效应协方差矩阵等。 Syntax 命令是目前所有软件包中最简单的。meta meregress 在可以应用于随机效应的约束方面也是最灵活的。
当研究人员想要分析来自多个研究的结果时,他们会使用元分析来合并结果并估计总体效应大小。现有的 meta 套件被用来进行标准和多变量的元分析。有时报告的效应大小被嵌套在更高层次的分组中,如地理位置(州或国家)或行政单位(学区)。同一组内(例如,区)的效应大小很可能是相似的,因此具有依赖性。在这种情况下,你可以使用多层元分析。多层元分析的目标是不仅要综合总体效应大小,而且要考虑到这种依赖性,并评估不同层次的效应大小之间的变化。新的估计命令 meta meregress 和 meta multilevel 是用来进行多层元分析的。假设我们有研究报告了两种教学方法对数学考试成绩y和y的抽样标准误差的影响(平均差异)。影响大小嵌套在学校内,学校嵌套在地区内。我们可以用. meta meregress y || district: || school:, essevariable(se)或. meta multilevel y, relevels(district school) essevariable(se)如果我们有协变量并想要包括随机斜率,我们可以使用meta meregress:. meta meregress y x1 x2 || district: x1 x2 || school:, essevariable(se)拟合模型后,后估计命令可用于计算多层次异质性统计,显示估计的随机效应协方差矩阵等。 Syntax 命令是目前所有软件包中最简单的。meta meregress 在可以应用于随机效应的约束方面也是最灵活的。
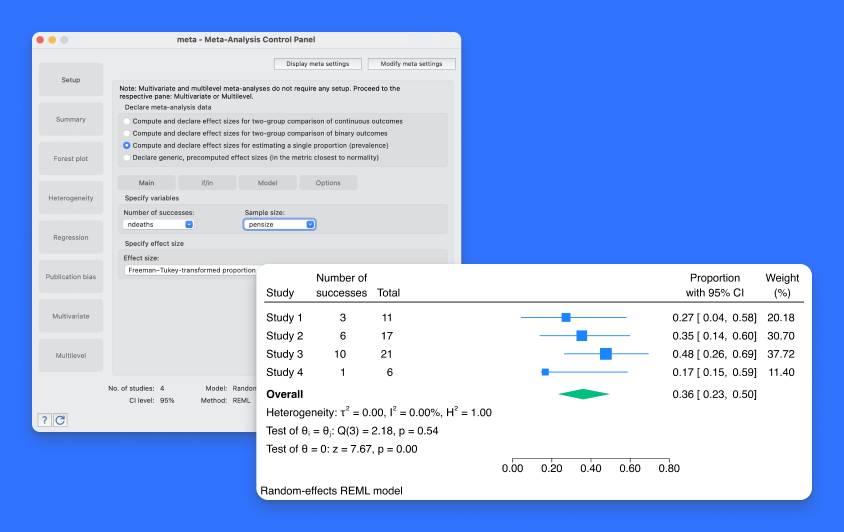 meta esize 命令对两个样本的二元或连续数据进行元分析,现在,它也对一个样本的二元数据进行元分析,也被称为比例的元分析或流行率的元分析。这些类型的数据通常出现在元分析研究中,当汇集来自各估计一个比例的研究结果时。例如,你可能有研究报告某种疾病的流行率或高中辍学学生的比例。在这种情况下,效应大小,如Freeman-Tukey转换的比例或 logit 转换的比例,通常在元分析中使用。在 meta esize 之后,使用 meta 套件中的其他命令进行进一步分析。例如,用 meta forestplot 创建森林图,通过将 subgroup()选项添加到元森林图来执行亚组分析,使用 meta summarize 汇总元分析数据,或者使用meta funnelplot构建漏斗图。患病率的元分析是最常见的用户要求添加到我们的元分析套件中。许多用户期待着对这种性质的研究进行分析。
meta esize 命令对两个样本的二元或连续数据进行元分析,现在,它也对一个样本的二元数据进行元分析,也被称为比例的元分析或流行率的元分析。这些类型的数据通常出现在元分析研究中,当汇集来自各估计一个比例的研究结果时。例如,你可能有研究报告某种疾病的流行率或高中辍学学生的比例。在这种情况下,效应大小,如Freeman-Tukey转换的比例或 logit 转换的比例,通常在元分析中使用。在 meta esize 之后,使用 meta 套件中的其他命令进行进一步分析。例如,用 meta forestplot 创建森林图,通过将 subgroup()选项添加到元森林图来执行亚组分析,使用 meta summarize 汇总元分析数据,或者使用meta funnelplot构建漏斗图。患病率的元分析是最常见的用户要求添加到我们的元分析套件中。许多用户期待着对这种性质的研究进行分析。
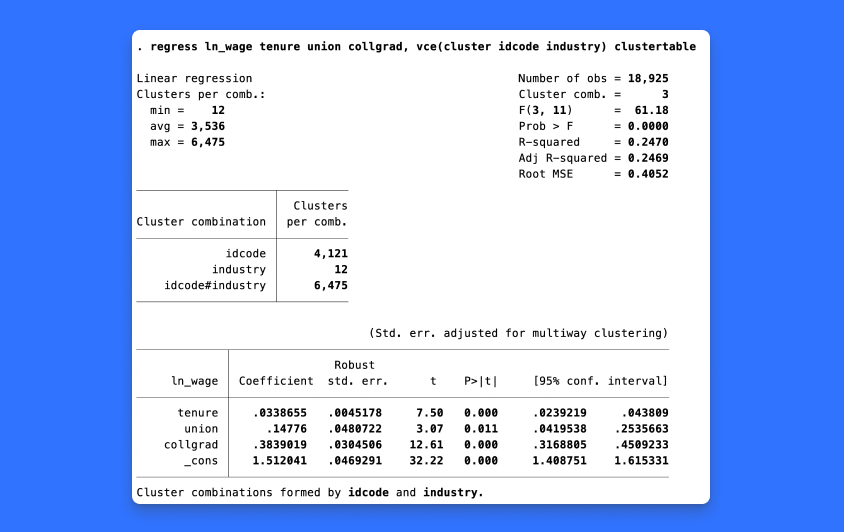 正确的标准误对于在研究中得出适当的推论至关重要。Stata 18 为 regress、areg 和 xtreg、fe 的线性模型提供了获得标准误差和置信区间的新方法。新方法的目的是在大样本近似法效果不佳时提供更好的推理。也许你的聚类数据只有几个聚类,或者每个聚类的观测值数量不均匀。您现在可以添加 vce(hc2-clustervar)选项来获得 hc2 聚类稳健标准误。也许你有一个以上的变量来识别你的数据中的聚类,你现在可以添加 vce(cluster clustvar1 clustvar2 ...)选项来获得多向聚类标准误。最近,社交媒体上有许多关于在各种情况下标准误的最佳选择的热烈讨论。
正确的标准误对于在研究中得出适当的推论至关重要。Stata 18 为 regress、areg 和 xtreg、fe 的线性模型提供了获得标准误差和置信区间的新方法。新方法的目的是在大样本近似法效果不佳时提供更好的推理。也许你的聚类数据只有几个聚类,或者每个聚类的观测值数量不均匀。您现在可以添加 vce(hc2-clustervar)选项来获得 hc2 聚类稳健标准误。也许你有一个以上的变量来识别你的数据中的聚类,你现在可以添加 vce(cluster clustvar1 clustvar2 ...)选项来获得多向聚类标准误。最近,社交媒体上有许多关于在各种情况下标准误的最佳选择的热烈讨论。
 当研究人员有几个集群的数据、集群之间的观测数量不均衡或两者兼有时,野聚类自助法为稳健推理提供了另一个新的选择。 新的 wildbootstrap 命令计算了用于检验线性回归模型参数的简单和复合线性假设的野聚类自助法 p 值和置信区间。你可以输入
当研究人员有几个集群的数据、集群之间的观测数量不均衡或两者兼有时,野聚类自助法为稳健推理提供了另一个新的选择。 新的 wildbootstrap 命令计算了用于检验线性回归模型参数的简单和复合线性假设的野聚类自助法 p 值和置信区间。你可以输入
. wildbootstrap regress y x1 x2 …
或
. wildbootstrap areg y x1 x2 …, absorb(x3)
或
. xtset id
. wildbootstrap xtreg y x1 x2 …
来分别拟合线性回归模型、带有大量虚拟变量集的线性回归模型或面板数据的固定效应线性回归模型,并获得野聚类自助法统计数据。这与上述新的标准误差很好地结合在一起,为用户提供了许多新的工具,用于线性模型中的稳健推断。
 流行病学家经常需要确定两种暴露是如何相互作用的,使受试者经历一个感兴趣的结果的风险更高。例如,你可能想研究香烟烟雾和石棉的暴露如何相互作用,增加肺癌的风险。使用新的 reri 命令,你可以在相对风险的加性模型中测量双向的相互作用,同时考虑到其他的 风险因素。
流行病学家经常需要确定两种暴露是如何相互作用的,使受试者经历一个感兴趣的结果的风险更高。例如,你可能想研究香烟烟雾和石棉的暴露如何相互作用,增加肺癌的风险。使用新的 reri 命令,你可以在相对风险的加性模型中测量双向的相互作用,同时考虑到其他的 风险因素。
研究人员可以从各种支持的模型中选择,如 Logistic、二项广义线性、泊松、负二项、Cox、参数生存、区间删失的参数生存和区间删失的Cox模型。他们可以通过使用三个相关的统计数据:RERI、可归属比例和协同指数来评估烟雾和石棉的相互作用的加性模型。
用户群体:流行病学、医学和健康研究人员。
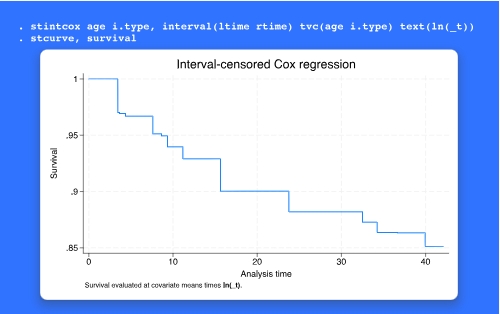 在事件-时间数据中,当一个感兴趣的事件(如癌症复发)的时间没有被直接观察到,但已知位于一个区间内时,就会发生区间删失。现有的 stintcox 命令适合半参数区间删失的Cox比例风险模型。在 Stata 18 中,stintcox 允许随时间变化的协变量。stintcox 现在支持每个受试者间隔多个记录的审查数据,其中包括每个受试对象每个检查时间的记录。这种格式可以很容易地适应时变协变量;数据记录了每个检查时间的协变量的值。每个受试者的多个记录数据也提供了指定当前状态数据的方便方法。stintcox 还提供了新的选项 tvc(varlist_t)和 texp(exp),这两个选项提供了一种方便的方式来包括时间迭代协变量,这些协变量是由 tvc()中指定的协变量与 texp()中规定的时间的不确定性函数之间的相互作用形成的。拟合一个模型后,标准和特殊利益的后评估功能可用,并适当地考虑时间变化的协变量。你可以使用新的 estat gofplot 命令来产生一个拟合的良好性图。你可以预测相对危险度。你可以使用 stcurve 来绘制生存者和相关函数。当你有多个记录数据时,你可以使用新的 stcurve 选项 attmeans 来评估协变量的特定时间均值的函数,或者使用新的选项 atframe(framename) 来评估 framename 中指定的变量值的函数。
在事件-时间数据中,当一个感兴趣的事件(如癌症复发)的时间没有被直接观察到,但已知位于一个区间内时,就会发生区间删失。现有的 stintcox 命令适合半参数区间删失的Cox比例风险模型。在 Stata 18 中,stintcox 允许随时间变化的协变量。stintcox 现在支持每个受试者间隔多个记录的审查数据,其中包括每个受试对象每个检查时间的记录。这种格式可以很容易地适应时变协变量;数据记录了每个检查时间的协变量的值。每个受试者的多个记录数据也提供了指定当前状态数据的方便方法。stintcox 还提供了新的选项 tvc(varlist_t)和 texp(exp),这两个选项提供了一种方便的方式来包括时间迭代协变量,这些协变量是由 tvc()中指定的协变量与 texp()中规定的时间的不确定性函数之间的相互作用形成的。拟合一个模型后,标准和特殊利益的后评估功能可用,并适当地考虑时间变化的协变量。你可以使用新的 estat gofplot 命令来产生一个拟合的良好性图。你可以预测相对危险度。你可以使用 stcurve 来绘制生存者和相关函数。当你有多个记录数据时,你可以使用新的 stcurve 选项 attmeans 来评估协变量的特定时间均值的函数,或者使用新的选项 atframe(framename) 来评估 framename 中指定的变量值的函数。
真正的半参数模型是对区间删失的事件-时间数据的建模,直到近年来方法上的进步,这些进步在 stintcox 命令中实现。方法上的进步还体现在对时变协变量的扩展上,现在这个命令中就有这些扩展。用户群体:任何对生存期或持续时间分析感兴趣的人,如生物统计学、经济学(作为持续时间分析的一部分)、流行病学、医学、政治学、机构研究或健康方面的研究人员。
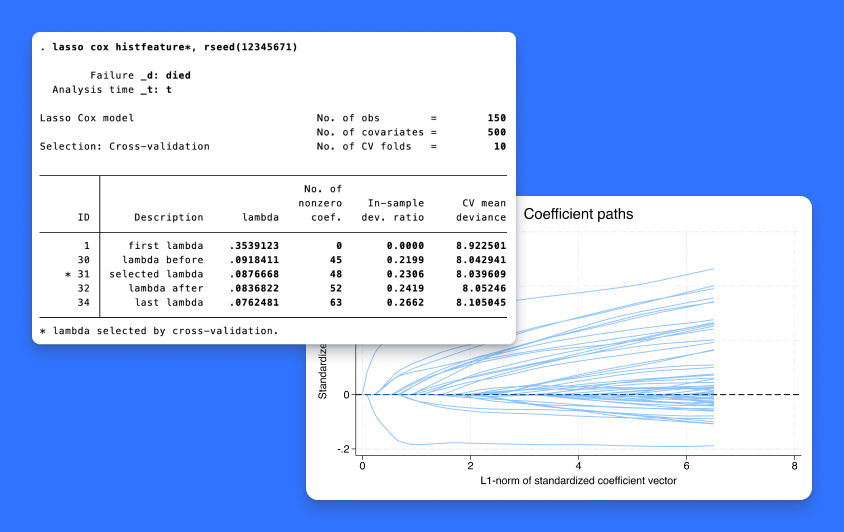 当我们有许多潜在的协变量时,我们使用 lasso 进行预测和模型选择。(当我们说很多的时候,我们指的是几百个,几千个,甚至更多。)我们以前介绍过 lasso 命令,对线性、logit、probit 和 Poisson 模型进行 lasso。在 Stata 18 中新增了用于 Cox 比例危险模型的 lasso。lasso cox 可以用来用套索选择协变量,并对生存时间数据拟合 Cox 模型。 elasticnet cox 同样可以用来用弹性网选择协变量并拟合 Cox 模型。 在 lasso cox 和 elasticnet cox 之后,你可以使用 predict 来预测危险比;使用 stcurve 来绘制生存函数、危险函数或累积危险函数;或者使用 lasso 和 elasticnet 之后的任何其他后估计工具来检查 lasso 的结果。
当我们有许多潜在的协变量时,我们使用 lasso 进行预测和模型选择。(当我们说很多的时候,我们指的是几百个,几千个,甚至更多。)我们以前介绍过 lasso 命令,对线性、logit、probit 和 Poisson 模型进行 lasso。在 Stata 18 中新增了用于 Cox 比例危险模型的 lasso。lasso cox 可以用来用套索选择协变量,并对生存时间数据拟合 Cox 模型。 elasticnet cox 同样可以用来用弹性网选择协变量并拟合 Cox 模型。 在 lasso cox 和 elasticnet cox 之后,你可以使用 predict 来预测危险比;使用 stcurve 来绘制生存函数、危险函数或累积危险函数;或者使用 lasso 和 elasticnet 之后的任何其他后估计工具来检查 lasso 的结果。
用户群体:任何对生存期或持续时间分析感兴趣的人,如生物统计学、经济学(作为持续时间分析的一部分)、流行病学、医学、政治学、机构研究或健康方面的研究人员。
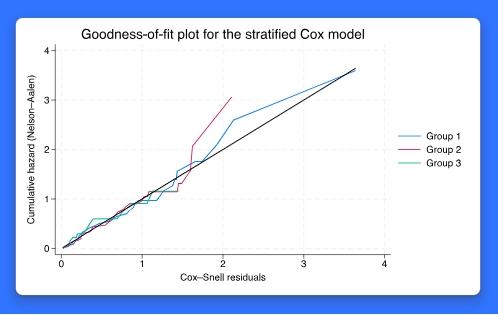 Stata 18 提供了新的estat gofplot命令来生成生存模型的拟合优度 (GOF) 图。您可以在四个生存模型之后使用它:右删失 Cox ( stcox )、区间删失 Cox ( stintcox )、右删失参数 ( streg ) 和区间删失参数 ( stintreg )。检查分层模型后的模型适合度或分别针对每个分组。
Stata 18 提供了新的estat gofplot命令来生成生存模型的拟合优度 (GOF) 图。您可以在四个生存模型之后使用它:右删失 Cox ( stcox )、区间删失 Cox ( stintcox )、右删失参数 ( streg ) 和区间删失参数 ( stintreg )。检查分层模型后的模型适合度或分别针对每个分组。
GOF 图可以直观地检查模型与数据的拟合程度。在生存分析中,这些检查基于所谓的 Cox–Snell 残差和假设,如果模型是正确的,这些残差应该具有标准的指数分布。从视觉上看,这个假设是通过根据估计的累积风险绘制残差来评估的——绘制的值越接近 45° 线,拟合越好(Cox 和 Snell 1968)。
1、参数和半参数生存模型
2、右删失和区间删失数据
3、累积风险函数的三个估计量
4、按组和分层模型
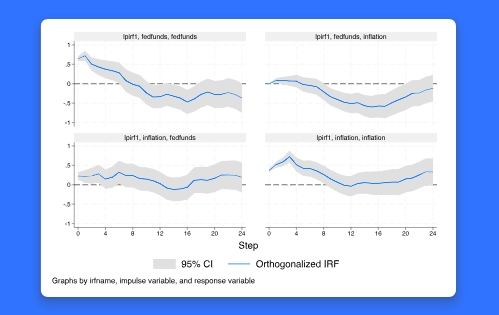 新的 Ipirf 命令提供了 IRFS 的局部投影。在时间序列分析中,局部投影法被用来估计冲击对结果变量的影响。例如,我们可以评估利率的意外变化对一个国家的产出和通货膨胀率的影响。
新的 Ipirf 命令提供了 IRFS 的局部投影。在时间序列分析中,局部投影法被用来估计冲击对结果变量的影响。例如,我们可以评估利率的意外变化对一个国家的产出和通货膨胀率的影响。
你可以输入:
. lpirf y1 y2
以获得 y1 和 y2 的 IRFS 的局部投影估计。您可以添加 exog()选项来估计动态乘数,这是内生变量对外生变量冲击的反应。新的 lpirf 命令与现有的 irf 命令无缝配合,允许您创建 IRFS、正交 IRFS 和动态乘法器的图形和表格。
与上面提到的线性模型一样,稳健标准误在IRF估计中往往很重要。稳健标准误和 Newey-West 标准误是可用的。
IRFS 的局部投影提供了基于向量自回归(VAR)模型的 IRFS 的替代方案。局部投影不受模型约束;因此,它们提供了更灵活的 IRF 系数。局部投影也允许更容易的假设检验。任何研究时间序列数据的人,包括经济学、政治学、金融学和公共政策的研究人员对此功能都会感兴趣。
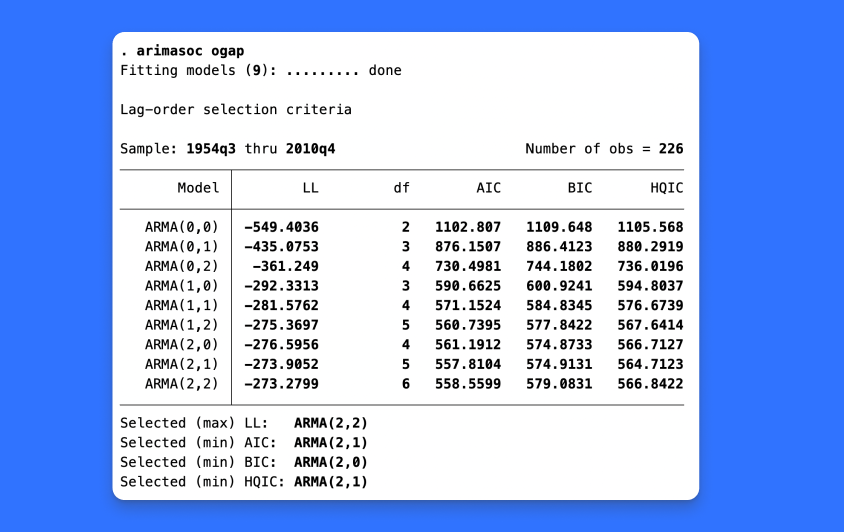 想为您的数据找到最好的ARIMA或ARFIMA模型吗?使用AIC、BIC和HQIC比较潜在模型。使用新的arimasoc和arfimasoc命令来选择自回归和移动平均项的最佳数量。
想为您的数据找到最好的ARIMA或ARFIMA模型吗?使用AIC、BIC和HQIC比较潜在模型。使用新的arimasoc和arfimasoc命令来选择自回归和移动平均项的最佳数量。
使用自回归移动平均(ARMA)模型的研究人员必须决定在其模型中包括自回归和移动平均参数的适当滞后数。平衡模型拟合与模型简约性的信息准则通常指导最大滞后数的选择。
arimasoc和arfimasoc通过拟合自回归积分移动平均值(ARIMA)或自回归分数积分移动平均数(ARFIMA)模型的集合并计算每个模型的信息标准来帮助模型选择。arimasoc和arfimasoc计算Akaike信息准则(AIC)、贝叶斯信息准则(BIC)和Hannan–Quinn信息准则(HQIC)。所选择的模型是信息标准值最低的模型。
1、ARIMA 和 ARFIMA 模型的模型选择
2、 AIC、BIC 和 HQIC 信息标准
 通常情况下,研究人员对估计一篮子商品的需求感兴趣。新的 demandys 命令提供了广泛的工具来计算需求,并通过计算相应的弹性来衡量商品需求对价格和支出变化的敏感程度。 我们可以用 demandys 来拟合八个不同的需求系统模型:
通常情况下,研究人员对估计一篮子商品的需求感兴趣。新的 demandys 命令提供了广泛的工具来计算需求,并通过计算相应的弹性来衡量商品需求对价格和支出变化的敏感程度。 我们可以用 demandys 来拟合八个不同的需求系统模型:
1、 Cobb–Douglas
2、 Linear expenditure system
3、Basic translog
4、Generalized translog
5、Almost ideal demand
6、Generalized almost ideal
7、Quadratic almost ideal
8、Generalized quadratic almost ideal
使用 estat 弹性命令,我们可以估计各种弹性支出弹性、未补偿的自有价格和交叉价格弹性以及补偿的自有物价和交叉价格的弹性,以探索需求对价格和支出变化的敏感程度。 由于有八种需求系统可供选择,demandys 命令为研究人员提供了很大的灵活性,可以选择符合其经验假设的需求系统技术。
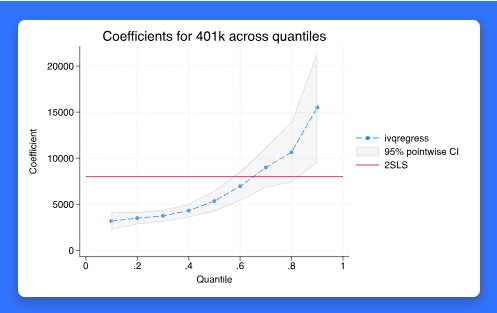 当我们想研究协变量对结果的不同量级的影响,而不仅仅是对精益的影响时,我们使用分位数回归。例如,我们可能对建立学生的年级分布模型感兴趣,以及它如何受到协变量变化的影响。现有的 qreg 命令适合于分位数回归模型,但是如果我们怀疑其中一个协变量是内生的呢?这种内生性可能是由于研究参与者的自我选择、模型中遗漏相关变量或测量误差等原因造成的。新的 ivqregress 命令允许我们对结果的分位数进行建模,同时用 IV 控制由内生性引起的问题。拟合 IV 分位数回归模型后,你可以用 estat coefplot 命令绘制各分位数指标的系数。你可以用 estat endogeffects 命令来检验内生性。还可以用 estat dualci 命令估计对弱工具具有稳健的双重置信区间。
当我们想研究协变量对结果的不同量级的影响,而不仅仅是对精益的影响时,我们使用分位数回归。例如,我们可能对建立学生的年级分布模型感兴趣,以及它如何受到协变量变化的影响。现有的 qreg 命令适合于分位数回归模型,但是如果我们怀疑其中一个协变量是内生的呢?这种内生性可能是由于研究参与者的自我选择、模型中遗漏相关变量或测量误差等原因造成的。新的 ivqregress 命令允许我们对结果的分位数进行建模,同时用 IV 控制由内生性引起的问题。拟合 IV 分位数回归模型后,你可以用 estat coefplot 命令绘制各分位数指标的系数。你可以用 estat endogeffects 命令来检验内生性。还可以用 estat dualci 命令估计对弱工具具有稳健的双重置信区间。
分位数回归在所有学科中都很流行,经济学、公共政策、政治学、公共卫生和管理学的研究人员都会特别感兴趣。
 分数结果很常见,你可能会对 401(K)养老金工厂的参与率、标准化考试的通过率、支出份额等进行建模。分数响应模型是一种灵活直观的方法,可以对介于 0 和 1 之间的结果进行建模。它们不存在将产生 0 和 1 之外的预测的线性模型的问题,也不存在在 0 和 1 处未定义的 log-odds 模型的问题。分数响应模型可以使用现有的 fracreg 命令进行拟合。
分数结果很常见,你可能会对 401(K)养老金工厂的参与率、标准化考试的通过率、支出份额等进行建模。分数响应模型是一种灵活直观的方法,可以对介于 0 和 1 之间的结果进行建模。它们不存在将产生 0 和 1 之外的预测的线性模型的问题,也不存在在 0 和 1 处未定义的 log-odds 模型的问题。分数响应模型可以使用现有的 fracreg 命令进行拟合。
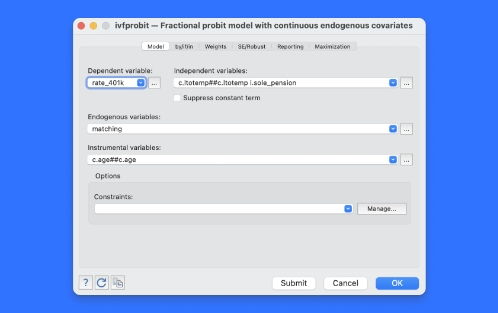
如果你担心你的一个或多个模型协变量是内生的,该怎么办?使用新的 ivfprobit 命令,您可以拟合分数因变量的模型,并考虑一个或多个协变量的内生性。
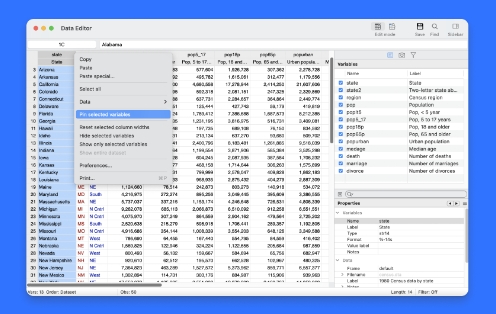 数据编辑器在 Stata 18 中有许多增强功能:
数据编辑器在 Stata 18 中有许多增强功能:
可固定的行和列。固定的行或列不会与其他数据一起滚动,因此当您滚动数据时,它们将保持在视图中。这对于与其他可能仅在滚动时可见的数据进行视觉比较非常有用。ID 变量是一个很自然的固定对象。
字符串数据的可调整大小的单元格编辑器。编辑字符串变量时,可以调整单元格编辑器的大小,以便在编辑时可以看到更多的字符串,而不会从单元格编辑器的视图中滚动出来。
截断文本的工具提示。任何单元格值如果太宽而无法适应其单元格列宽,则会截断以适应。将鼠标指针悬停在具有截断文本的单元格上,将显示一个工具提示,其中包含该单元格的值而不截断。
比例宽度字体支持。数据编辑器现在支持等宽字体。这提高了数据的可读性,并允许在不需要滚动的情况下一次显示更多的变量。如果愿意,仍然可以使用单格字体。
在列标题中显示变量标签。变量标签现在可以显示在列标题中变量名称的正下方。这对于查看具有变量标签的简短和非描述性变量名的数据集非常有用。用于隐藏或显示值标签的新键盘快捷方式。在查看数值及其对应标签之间快速切换。
Do文件编辑器在 Stata 18 中也有增强功能:
自动备份。在 Do 文件编辑器中打开的文档会定期保存到磁盘上的备份文件中。其中包括尚未保存到磁盘的新文档。如果您的计算机在您有机会保存对文档的更改之前断电或崩溃,您未保存的更改仍然可以恢复。若要恢复未保存的更改,请在 Do 文件编辑器中再次打开文档。如果在与文档相同的位置找到备份文件,系统将提示您恢复备份文件或打开上次保存到磁盘的文档。恢复备份文件只需将其加载到 Do 文件编辑器中;除非您选择这样做,否则它不会重写保存到磁盘的文档。
语法高亮显示用户定义的关键字。Statas Do 文件编辑器现在包括语法高亮显示用户定义的关键字的功能。这将允许您在语法上突出显示您最喜欢的社区贡献的命令。您只需创建一个特殊命名的关键字定义文件,其中包含关键字列表,Stata 将使用可设置的颜色和字体样式(如粗体或斜体)在语法上突出显示这些关键字。您甚至可以创建一个全局关键字定义文件,该文件可以与同一台计算机的所有用户共享。每个用户仍然可以创建自己的本地关键字定义文件,全局文件和本地文件中的关键字都将加载到Do文件编辑器中。
使用一致的 AIC (CAIC) 比较模型。或者,对于小样本量,使用校正后的 AIC (AICc)。
改进后的样条生成工具——新的makespline——支持 B 样条并一次为多个变量生成样条。
同时逼近多个数值积分。自适应 Gauss–Kronrod 和 Simpson 方法。对奇异点的鲁棒性。
新的基于 Boost 的正则表达式函数
允许不同的正则表达式语法
正则表达式是处理字符串数据的强大工具。Stata 的正则表达式在 Stata 18 中变得更加强大,具有更多功能。
可重现的报告使我们能够在分析发生变化时简化呈现我们的发现的过程。无论我们的工作方向发生变化还是我们实施同行的反馈,用我们的研究结果创建一份报告很少是一次性的任务。Stata 的可重现报告功能使我们能够随着分析的变化轻松修改和调整我们的报告。
在 Stata 18 中,我们为 putdocx 和 putexcel 添加了功能,允许您进一步自定义可重现的报告。现在您可以使用putexcel添加页眉、页脚和分页符。您还可以冻结工作表中的一行或一列;这使您可以在视图中保留该行或列中的信息,同时滚动浏览工作表的其余部分。此外,您可以创建命名的单元格区域以简化公式的使用。我们还使用 putdocx 添加了对书签的支持; 只需将您的文本格式化为书签,并根据需要链接到它。此外,在将图像添加到 .docx 文件时,您现在可以为要由语音软件读取的图像指定替代文本。
putdocx中的新功能
1、在段落和表格中包含书签
2、包括可供图像语音软件阅读的替代文本
3、包括可缩放矢量图形 (.svg) 图像
putexcel中的新功能
1、将工作表冻结在特定的行或列
2、在特定行或列插入分页符
3、在工作表中插入页眉和页脚
4、在单元格中包含超链接
5、创建命名单元格区域
想要散点图中点的颜色来反映年龄组吗?或者想要条形图中条形的颜色反映收入水平?或者想要点图中点的颜色来反映健康状况?
在 Stata 18 中,新的colorvar()选项允许许多双向图根据变量的值改变标记、条形等的颜色。
1、使用标记颜色来传达可变信息
2、连续或离散地改变颜色
3、指定颜色应如何链接到颜色变量的值
4、适用于许多双向图,包括散点图和条形图
您在内存中使用多个数据集,也称为帧。当这些数据集相关时——也许它们在同一个项目中使用或相互链接——你现在可以将它们捆绑在一个框架集中。将所有数据集保存在一个文件中。以后一起使用它们。
软件特点
1、掌握您的数据
(1) 同时管理多个数据集
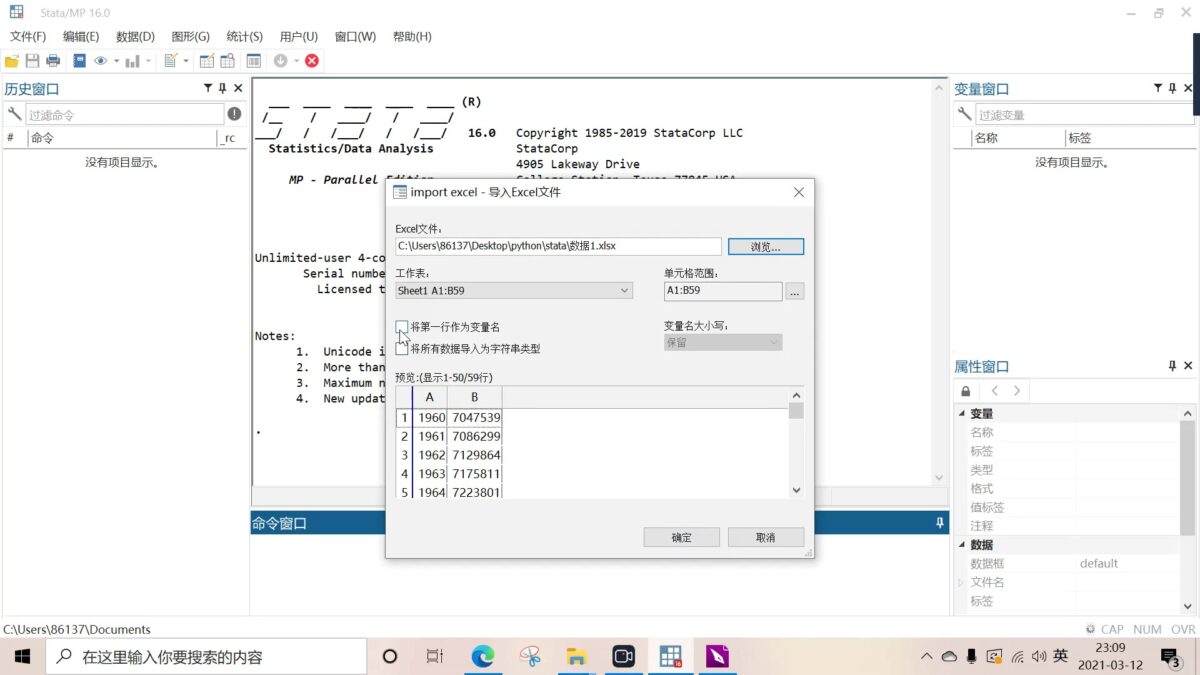
(2) Import, export
(3) JDBC, ODBC, SQL
(4) 排序,匹配,合并,加入,追加,创建
(5) 内置电子表格
(6) unicode
(7) 处理文本或二进制数据
(8) 在本地或在Web上访问数据
(9) 收集组间的统计信息
(10) BLOBs -strings可以容纳整个文档
(11) 数十亿个观测值
(12) 数万个变量数
(13) 生存数据, 面板数据, 多级数据, 调查数据, 多重插补数据, 分类数据, 时间序列数据
(14) 更重要的是,支持您的所有数据科学需求。
2、广泛的统计功能
3、出版质量的图形
Stata可以轻松生成出版品质,风格独特的图形。
您可以指向并单击以创建自定义图形。或者,您可以编写脚本以可重现的方式生成数百或数千个图形。将图形导出为EPS或TIFF进行发布,导出为PNG或SVG进行Web导出,或者导出为PDF进行查看。使用集成的Graph Editor,您可以单击以更改有关图形的任何内容或添加标题,注释,线条,箭头和文本。
4、自动报告
(1) 动态Markdown文档
(2) 创建Word文档
(3) 创建PDF文档
(4) 创建Excel文件
(5) 可定制的表格
(6) 图形方案
(7) Word,HTML,PDF,SVG,PNG
5、真正可重复的研究
很多人谈论可重复的研究。Stata 已经致力于它超过30年。我们不断添加新功能; 我们甚至从根本上改变了语言元素。不管。Stata 是唯一具有集成版本控制的统计软件包。如果你在1985年编写了一个脚本来执行分析,那么同样的脚本仍然可以运行,并且今天仍会产生相同的结果。您在1985年创建的任何数据集,今天都可以阅读。在2050年也是如此.Stata 将能够运行你今天所做的任何事情。
6、PyStata — Python集成
(1) 以交互方式调用Python或将Python嵌入到您的Stata代码中。
(2) 从Python调用Stata并从IPython环境调用Stata代码。
(3) 在Jupyter Notebook中使用Stata。
(4) 在Stata和Python之间无缝传递数据和结果。
(5) 从Python内部使用Stata分析。
(6) 在Stata中使用任何Python包
(7) Matplotlib和Seaborn进行可视化
(8) 美丽的汤和Scrapy用于网页抓取
(9) NumPy和熊猫进行数值分析
(10) TensorFlow和scikit-learn用于机器学习
7、我们的每个数据管理功能都经过充分解释和记录,并在实际示例中显示。每个估算器都有完整的文档记录,包括几个关于实际数据的示例,以及如何解释结果的真实讨论。这些示例为您提供数据,以便您可以在 Stata 中工作甚至扩展分析。我们为您提供每个功能的快速入门,展示一些最常见的用途。想要更多细节?我们的方法和公式部分提供了计算内容的具体信息,我们的参考文献为您提供了更多信息。 Stata 是一个很大的包,所以有很多文档 - 超过17,000页,共33卷。但不要担心,键入 help ,Stata 将搜索其关键字,索引,甚至社区提供的包,为您带来您需要了解的主题。一切都在Stata内可用。
8、值得信赖
我们不仅编程统计方法,还对它们进行验证。您从 Stata 估算器看到的结果取决于与其他估算器的比较,一致性和覆盖率的蒙特卡洛模拟以及我们的统计人员进行的广泛测试。我们运送的每一个Stata都通过了一套认证套件 ,其中包括370万行测试代码,可产生560万行输出。我们对560万行输出中的每个数字和一段文本进行认证。
9、简单易用
Stata 的所有功能都可以通过菜单,对话框,控制面板,数据编辑器,变量管理器,图形编辑器甚至 SEM 图形生成器来访问。您可以通过任何分析指向并单击您的方式。如果您不想编写命令和脚本,则不必这样做。即使您指向并单击,也可以记录所有结果,然后将其包含在报告中。您甚至可以保存您的操作创建的命令,并在以后重现您的完整分析。
10、容易掌握
Stata 执行任务的命令直观易学。更好的是,您从执行任务中学到的所有知识都可以应用于其他任务。例如,您只需在任何命令中添加“ gender =“ =” female“,即可将分析范围限制为样本中的女性。您只需将 vce(robust)添加到任何估计量中,即可获得对许多常见假设都具有鲁棒性的标准误差和假设检验。
一致性更加深入。您从数据管理命令中学到的知识通常适用于估算命令,反之亦然。还有一整套后估计命令,用于执行假设检验,形成线性和非线性组合,进行预测,形成对比,甚至使用交互作用图执行边际分析。在几乎每个估算器之后,这些命令都以相同的方式工作。
排序命令以读取和清除数据,然后执行统计测试和估计,最后报告结果是可重复研究的核心。Stata 使所有研究人员都可以访问此过程。
11、易于自动化
每个人都有他们一直在做的任务 - 创建特定类型的变量,生成特定的表,执行一系列统计步骤,计算 RMSE 等。可能性是无穷无尽的。Stata 有数千个内置程序,但可能拥有相对独特的任务或者您希望以特定方式完成的任务。如果您编写了一个脚本来执行给定数据集上的任务,则可以轻松地将该脚本转换为可用于所有数据集,任何变量集以及任何观察集的内容。
12、易于扩展
自动化的一些内容可能非常实用。只需一点代码,就可以将自动化脚本转换为 Stata 命令。支持 Stata 官方命令支持的标准功能的命令。可以与使用官方命令相同的方式使用的命令。
13、高级编程
Stata 还包括一种高级编程语言-Mata。Mata 具有您期望在编程语言中使用的结构,指针和类,并为矩阵编程添加了直接支持。Mata 既是一个用于操作矩阵的交互式环境,也是一个可以生成编译和优化代码的完整开发环境。它包括处理面板数据的特殊功能,对实际或复杂矩阵执行操作,为面向对象编程提供全面支持,并与 Stata 的各个方面完全集成。
14、跨平台兼容
Stata 将在 Windows,Mac 和 Linux / Unix 计算机上运行;但是,我们的许可证不是特定于平台的。这意味着,如果您有一台 Mac 笔记本电脑和 Windows 台式机,则不需要两个单独的许可证即可运行Stata。您可以在任何受支持的平台上安装 Stata 许可证。Stata 数据集,程序和其他数据可以在不进行翻译的情况下跨平台共享。您还可以快速轻松地从其他统计数据包,电子表格和数据库中导入数据集。




 软件推荐
软件推荐- 目前已有69188+家客户获取报价
- 北京华航唯实机器人科技股份有限公司正在询价
- 惠生工程(中国)有限公司正在询价
- 大连理工大学正在询价
- 云南力辰建设工程有限公司正在询价
- 武汉开目正在询价
- 多纳尔科技正在询价
- 国网先行河北能源科技有限公司正在询价
- 贵州允正工程质量检测有限公司正在询价
- 赣交院正在询价
- 陕西建工集团正在询价
- 广东正在询价
- 杭州软库正在询价
- 广东科贸职业学院正在询价
- 厦门万森特斯正在询价
- 华南理工大学正在询价
- 昆山轴正在询价
- 国家数字化设计与制造创新中心正在询价
- 北京工业大学正在询价
- 苏州迅镭激光正在询价
- 吉林大学正在询价
- LECHUANG VIET NAM MODEL DESIGN CO. LTD正在询价
- 北京节能技术监测中心正在询价
- 合肥九韶正在询价
- 江苏金网检测认证有限公司正在询价
- 智秦时代数字出版技术有限公司正在询价
- 北京维开科技有限公司正在询价
- 上海惠程信息科技有限公司正在询价
- 武汉德宝装备股份有限公司正在询价
- 广东亦通水务科技有限公司正在询价
- 潍坊市恒瑞制冷设备有限公司正在询价
- 智慧网络正在询价
- 晋能控股集团正在询价
- 东方电气(福建)创新研究院有限公司正在询价
- 昆山轴研正在询价
- 小信科技正在询价
- 东莞永隆电器有限公司正在询价
- 中山市景弘酒店有限公司正在询价
- 广东/佛山正在询价
- 河北/沧州正在询价
- 盛宏鑫正在询价
- 甘肃振讯智能科技有限公司正在询价
- 易比易电器有限公司正在询价
- 中国建筑土木建设有限公司正在询价
- 华中科技大学正在询价
- 海昌智能正在询价
- 中尧煤机正在询价
- 南京长善正在询价
- 永福县巨鑫建材有限公司正在询价
- 黄金土农资有限公司正在询价
- 长春市鸿昊汽车零件加工有限责任公司正在询价
- 众才汇人力资源公司正在询价
- 陕西/西安正在询价
- 上海理工正在询价
- 浙江工业大学正在询价
- 航天一院正在询价
- 新蔡月亮湾医院有限公司正在询价
- 西安科宇馨盛正在询价
- 信恒服装正在询价
- 研發正在询价
- 三只人正在询价
- 保健机械产品正在询价
- 华为技术有限公司正在询价
- 河北辛集市雪龙机械制造有限公司正在询价
- 保山学院正在询价
- 北京元年科技股份有限公司正在询价
- 渝北区职教中心正在询价
- 湖北民族大学正在询价
- 龙岩市新罗区疾病预防控制中心正在询价
- 祥裕模具正在询价
- 苏州集合石智控科技有限公司正在询价


